背景
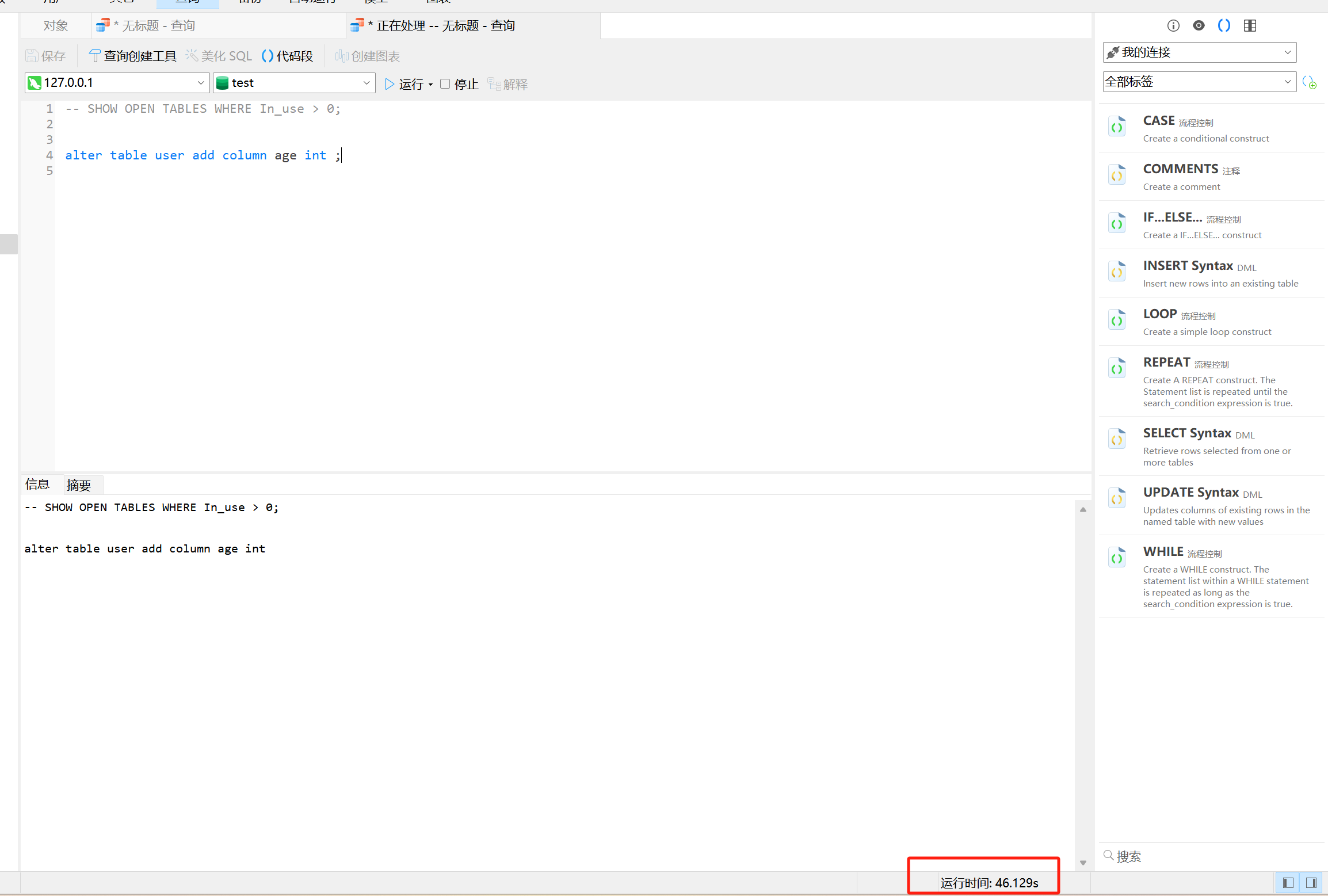
最近软路由经常出问题:
- clash 突然死掉了, 发现后我就把它重启了, 重启过程中有点卡顿,但是我没有在意
- 整个软路由设备r2s 亮红灯, GUI 界面都登录不上去了
排查过程
- 重启若干次之后终于可以 ssh 上去了,这个时候要注意,要持续监测服务是否启动, 因为服务器有问题的时候,正常时间1min 可能是启动不了了,需要等2分钟, 要注意的是,等3分钟可能因为现在的问题, 服务器又挂了,所以多试几次
- 发现uptime 很高
1 | x@amanoswrt:~# uptime |
查看CPU数量
1 | root@amanoswrt:~# nproc |
这里有1个例子来描述系统有多忙:
假设你的服务器是 2核CPU,那么负载常态是4,意味着系统负载是CPU核心数的2倍,非常繁忙。如果是 8核CPU,负载为4则属于可接受范围,但常态是4也值得关注。
发现cpu 不高
我之前只会用 top 命令, 然后加上 P (shift + p) 来按照CPU来排序,但是发现最高的也才1%, CPU不忙呀?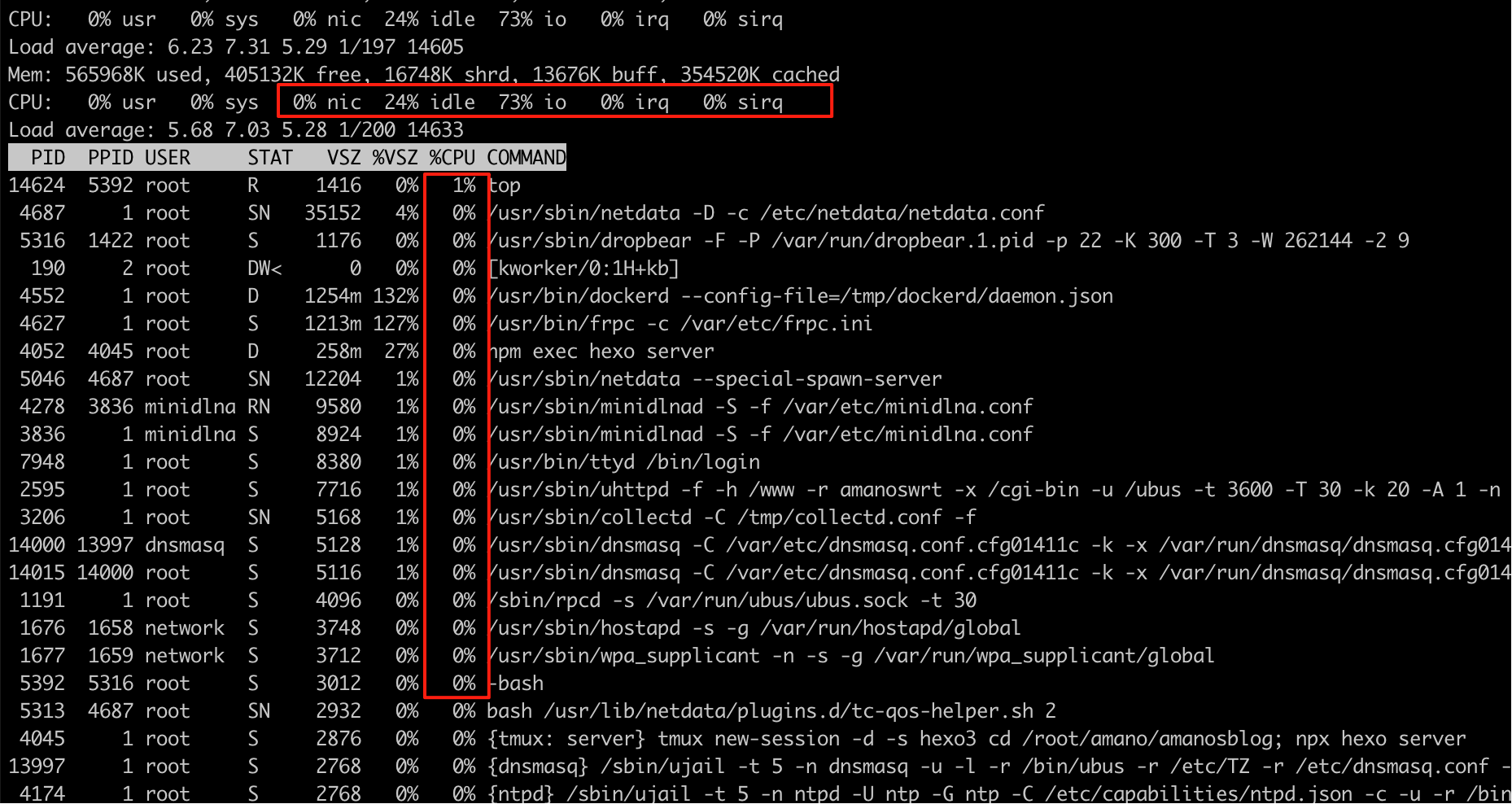
问了llm发现,可以通过第一行排查
1 | CPU: 0% usr 0% sys 0% nic 24% idle 73% io 0% irq 0% sirq |
我的负载在于等待硬盘
- 可以使用iotop来排查是哪个进程使用那么高的io, 这里我使用的是pidstat
1
2# 每隔2秒报告一次所有进程的磁盘I/O统计
pidstat -d 2
结果
1 | 18:41:52 UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command |
找到问题了, minidlnad 导致的
思考
第一次遇到性能瓶颈是IO. 与此同时,我想到之前有一次我有一篇文章使用rsync 的,使用它的原因的是当初使用自动同步 anything 的时候导致直接连不上n2s ,当时不知道原因, 现在想来现象很像, 原因估计也是一样的。 good to address this problem。